심리상담 챗봇 구현하기
좌충우돌 챗봇 구현하기
이번 포스팅에서는 언어 모델 구현 방법에 대해 설명하려 합니다. 보통 딥러닝 쪽 공부해보고자 진입하시는 분들의 공부 방향은 다음과 같을 것 같습니다.
머신러닝 개념 이해 -> 딥러닝 개념 이해 -> Vision/NLP 분야를 좀 더 심도있게 공부
저는 위 과정을 거치고 자연어 처리 분야를 제 주무기로 삼아, 열심히 연구 및 공부 중입니다. 그래서 오늘은 NLP 분야에서도 가장 끝단에 있는 챗봇에 대해 알아보고자 합니다. 챗봇과 관련된 오픈소스나 깃에 공개되어 있는 코드들은 많습니다. 하지만 이제 막, 처음 챗봇을 연습삼아 구현해보고자 하시는 분들에게는 git에 있는 Readme 파일(튜토리얼)만 보고서 구현해보기가 쉽지 않습니다. 가장 밑단부터 세세하게 설명되어 있지 않기 때문에, 그냥 깃 클론해서 뚝딱뚝딱 실행이 되지 않죠. 이리저리 헤매고 맨땅에 헤딩도 하고, 그런 시간 소모 과정이 꽤나 필요합니다. 더군다나, 리소스가 많이 필요한 실습들은 코랩에서 진행해야 합니다. 로컬 pc에서 실습하는 환경과는 다소 다른 부분이 있어서, 환경 세팅을 따로 해줘야 합니다.
그래서 이번 포스팅에서는 Colab에서 실습을 진행하는 과정을 밑단부터 세세하게 제가 설명드려, 해당 블로그를 참고하시는 분들은 다소 덜 돌아갈 수 있게 하는 정보를 드리려 합니다.
우선 오늘 만들어 볼 챗봇은 심리상담을 해주는 챗봇입니다.
해당 챗봇 구현의 레퍼런스는 다음과 같습니다.
- 언어모델 : KoGPT2(SKTAI 제공)
- 파인튜닝할 데이터 셋 : chatbot_data.txt (송영숙님 제공), wellness_dialog.txt(AI허브)
- 심리상담 챗봇 코드 : 김성환님 깃허브
여기서, chatbot_data.txt를 전처리하고 wellness_dialog.txt를 전처리한 후 두 파일을 합쳐서 챗봇을 훈련시키겠습니다. 이렇게 구성하기 위해 파이썬 코드를 따로 직접 구현하였습니다.
제가 참고한 원천 소스들은 아래 URL로 달아놓았습니다.
제가 챗봇을 구동시킬 환경은 Colab입니다. 구글에서 제공하는 플랫폼으로 머신러닝 관련 코드를 실행해보기에 적합합니다. GPU도 제공해주고요. 자 이제 시작해보겠습니다.
ㄱ.폴더 계층도 만들기
타인의 코드를 클론해와서 구현할 때, 진척이 잘 안되는 경우가 보통 폴더 경로의 차이에서 발생합니다. 분명히 똑같이 구성했는데 왜 내 PC에서는 안돼?? 퍼블릭 라이브러리를 import 하는 줄 알았는데, 나중에 알고 보니 개인 로컬 폴더에 있는 파일을 import 해오거나, 이런 경우들이 많습니다.
일단, 다음 사진과 같이 폴더 구조를 만들었습니다.
내 드라이브(구글드라이브) / RogerHeederer / ChatBot / KoGPT2_Wellness
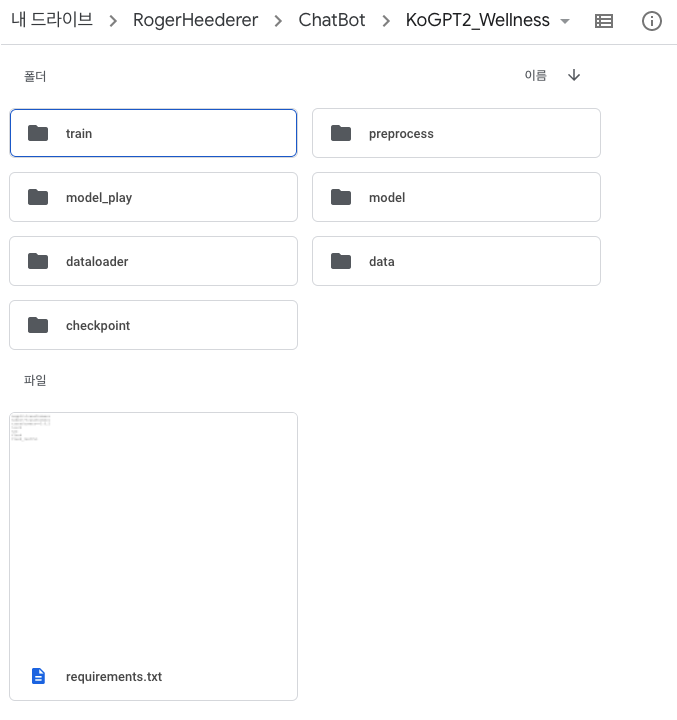
총 7개의 폴더와 requirements.txt (환경 세팅) 파일이 있습니다.
각 폴더에 대해 사용 순서대로 설명 드릴게요.
(1) data 폴더
해당 폴더에는 언어 모델이 학습할 데이터가 담겨져 있습니다. 이 폴더 안에는 chatbot_data.txt, wellness_dailog_dataset.xlsx 두 파일이 담겨있습니다. 해당 파일들은 오픈 데이터 셋으로서, 누구나 다운로드 받을 수 있습니다.
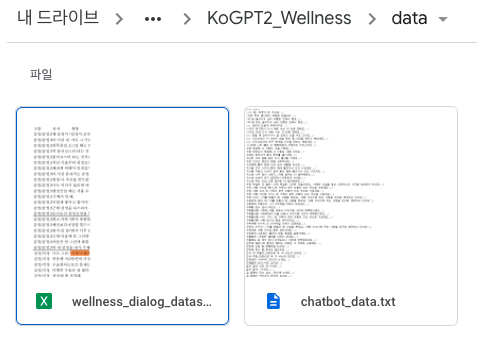
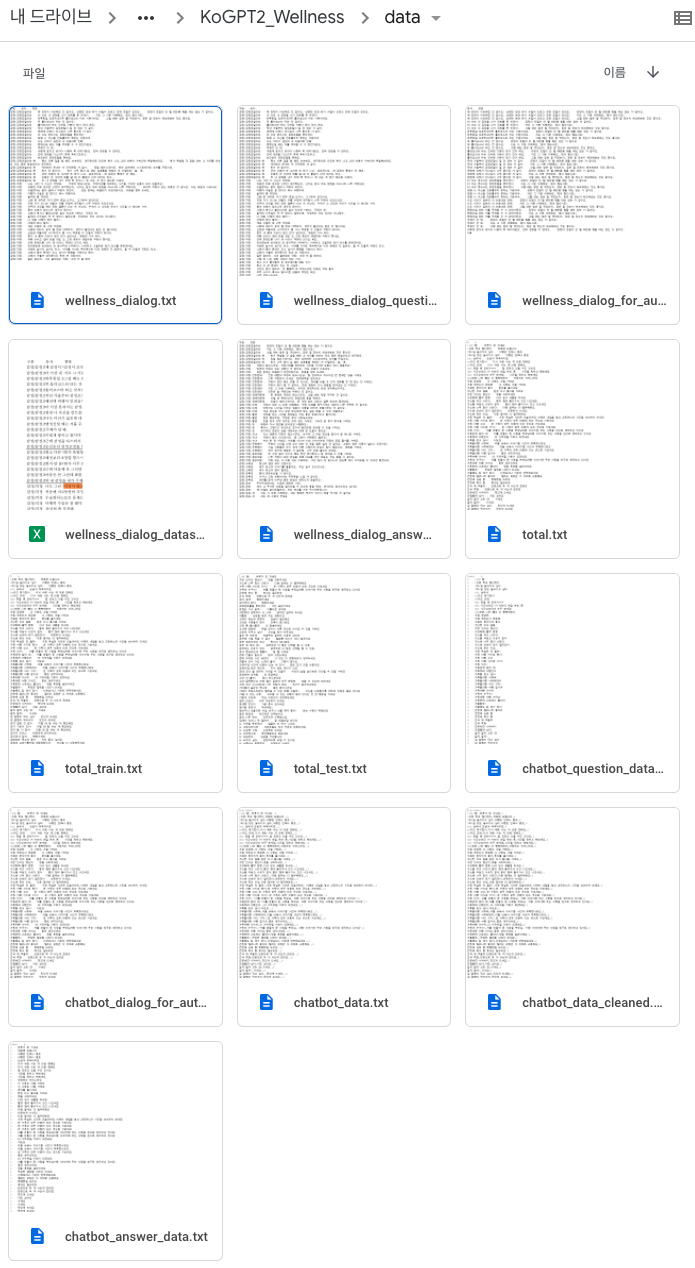
(2) preprocess 폴더
data 폴더 안에 있는 2개의 파일을 베이스로, 전처리 작업을 진행해주는 training_data.py 파일이 들어 있습니다. 이 전처리 작업 파일은 위 2개의 베이스 파일을 이용하여 언어 모델을 학습시키기 위해 적합한 데이터 형태로 재가공하여 새로운 파일들을 만들어 줍니다. 이 작업이 완료되면, chatbot_data.txt, wellness_dialog_dataset.xlsx 외에 11개 파일이 추가적으로 생성됩니다.
- Wellness dataset에 파생된 데이터 셋들
- 카테고리 / 질문 데이터 셋
- 카테고리 / 답변 데이터 셋
- 질문 / 답변 데이터 셋 (Autoregressive 형태)
- 질문 / 답변 데이터 셋 + 토큰 적용
- Chatbot dataset에 파생된 데이터 셋들
- 전처리(쌍따옴표, 온점 제거)된 데이터 셋
- 카테고리 / 질문 데이터 셋
- 카테고리 / 답변 데이터 셋
- 질문 / 답변 데이터 셋(Autoregressive 형태)
- 질문 / 답변 데이터 셋 + 토큰 적용
- Wellness Autoregressive + Chatbot Autoregressive 합친 최종 데이터 = total.txt
- 합친 최종 데이터를 train 셋과 test 셋으로 나눈 데이터 셋 = total_train.txt, total_test.txt
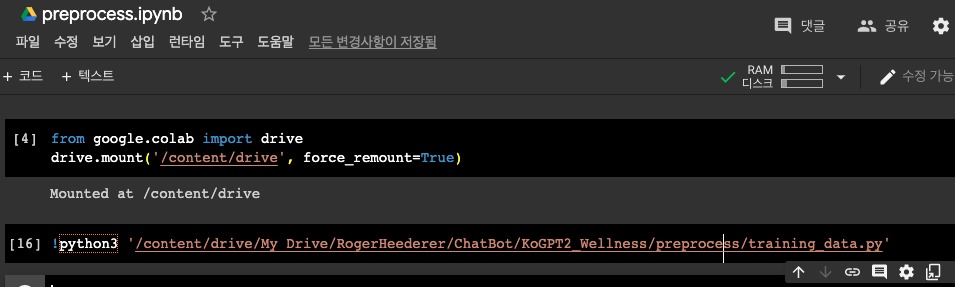
training_data.py 파일을 colab에서 실행시키기 위해서는 우선 training_data.py 파일을 업로드 합니다. 그리고 .py를 실행시킬 .ipynb 파일을 만듭니다. .ipynb 파일에서 코랩과 구글 드라이브를 연동시켜 주고, 업로드한 파이썬 파일을 실행시켜 줄 수 있는 명령어를 작성합니다. 아래 그림과 같습니다.
(3) dataloader 폴더
해당 폴더 안에는 total_data_load.py 파일이 있습니다. 이 파일은 앞서 전처리 된 파일 중 질문 답변 형식으로 꾸린 후 합친 total.txt 파일이 있습니다. 해당 파일을 KoGPT2언어 모델에 넣기 위해 “Dataset” 형태로 변형화 하는 작업을 진행해줍니다. 세부적인 코드 흐름은 해당 파일을 열어보고 분석해보시길 바랍니다.
(4) train 폴더
해당 폴더 안에는 train-kogpt2-by-total.ipynb 파일이 있습니다. 여기서는 GPU 연결 및 구글드라이브와 연동을 하고, dataloader를 통해서 TotalAutoRegressiveDataset을 불러옵니다. 그리고 에폭, 배치사이즈, 학습 저장 주기, 학습률 등 하이퍼파라미터를 지정합니다. 그 후 DialogKoGPT2 모델을 초기화 한 후에, 학습을 시작합니다. 저는 6 에폭을 돌렸고, 1 에폭당 약 1시간 7분 정도 학습시간이 소요되었습니다. 그리고 체크포인트를 설정하여 일정 텀 단위로 학습된 모델이 저장되도록 만들었습니다.

(5) run 폴더
해당 폴더에는 kogpt2-text-generation.py 파일이 있습니다. 이 파일을 colab에서 실행시키려면 다음의 명령어를 입력하세요.
!python3 ‘경로/kogpt2-text-generation.py’
데이터 로딩이 다 끝나면, 앞서 학습된 모델 및 모델이 가진 파라미터들을 불러온 후 실행을 해보고 챗봇과 대화하는 단계입니다. chatbot_data를 추가해서 학습을 해서 그런건지 wellness 데이터만을 넣고 학습시킨 모델(김성환님 깃허브)의 답변과는 조금은 다른 답변을 생성하는 모습을 확인할 수 있습니다.

Reference
- https://github.com/nawnoes/WellnessConversationAI
- https://github.com/songys/Chatbot_data
- https://github.com/haven-jeon/KoGPT2-chatbot