Confusion Matrix
True, False, Positive, Negative
이번 포스팅에서는 혼동 매트릭스에 대해 설명드리고자 합니다. 머신 러닝 기초를 공부하시면서 다들 한번씩은 보셨을 내용입니다. 그런데 곧잘 잊어버리는 개념이기도 합니다. 꽤 헷갈리거든요. 저 같은 경우는, 직관적으로 잘 와닿지 않아서 몇몇 예제들을 찾아보다가, ‘에라이 더 헷갈리네. 다음에 봐야지’하고 계속 넘겼던 개념입니다.
머신 러닝 지도학습에서는 전체 문제에서 예측값과 정답값이 일치하는 케이스를 선별하여 추려냅니다. 그리하여 정확도(Accuracy)를 계산하죠. 하지만 이 정확도라는 수치는 어떤 문제를 맞췄고, 틀렸는지에 대한 세부적인 내용은 알려주지 않습니다. 단순히 전체 몇 문제중에 몇 문제를 맞춰서 정확도가 ??이다 라고 알려주는 수치입니다.
이를 설명하기 위해 나온 개념이 혼동 행렬입니다. 혼동 행렬을 설명하는 여러가지 예시들이 있습니다. 저는 그 중에 가장 직관적으로 이해가능한 양성, 음성 예시로 설명하겠습니다.
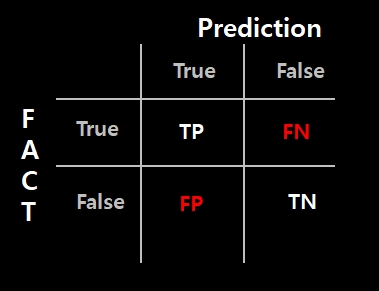
위 표의 열은 예측값을 나타내며, 행은 실제값을 나타냅니다. 예측 값에는 True, False 실제값에도 True, False 경우의 수가 있습니다.
True : 정답을 맞춘 경우 False : 정답을 맞추지 못한 경우
Positive(양성), Negative(음성) : 예측값
TP(True Positive) : 양성이라고 예측했는데, 실제값도 양성이라 정답을 맞춤
TN(True Negative) : 음성이라고 예측했는데, 실제값도 음성이라 정답을 맞춤
FN(False Negative) : 음성이라고 예측했는데, 실제값은 양성이라 오답
FP(False Positive) : 양성이라고 예측했는데, 실제값은 음성이라 오답
위 개념을 사용하여 정확도, 정밀도, 재현률, F1 Score 개념이 등장합니다.
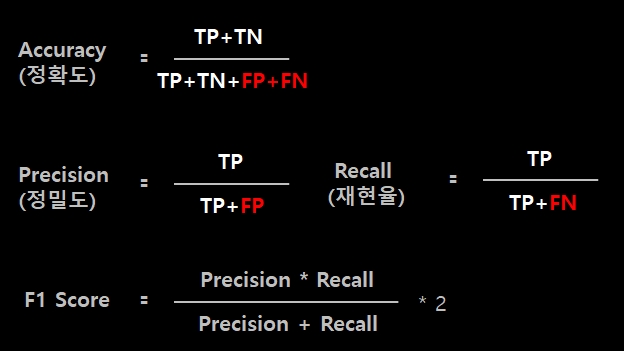
- 정확도 : 전체 경우의 수 중에, 맞춘 비율을 나타냅니다.
- 정밀도 : 양성이라고 예측한 전체 케이스 중에서 TP의 비율
- 재현룰 : 실제값이 양성인 데이터의 전체 케이스 중에서 TP의 비율
즉, 양성 데이터 중에 얼마나 양성인지를 예측해냈는지? - F1 Score : 정밀도와 재현율의 조화평균 값. 모델의 예측 성능을 측정할 때 자주 쓰이는 수치