Ensenble
Ensenble, Bagging and Boosting
이번 포스팅에서는 Ensenble. 앙상블에 대해 포스팅하고자 합니다. 앙상블을 한마디로 표현하자면, “백지장도 맞들면 낫다”로 정의할 수 있습니다. 힘을 모아 더 쉽게 해결한다는 뜻이죠. 즉, Classfication Model을 여러 종류로 조합해서 더 나은 성능을 이끌어 내는 방법론입니다.
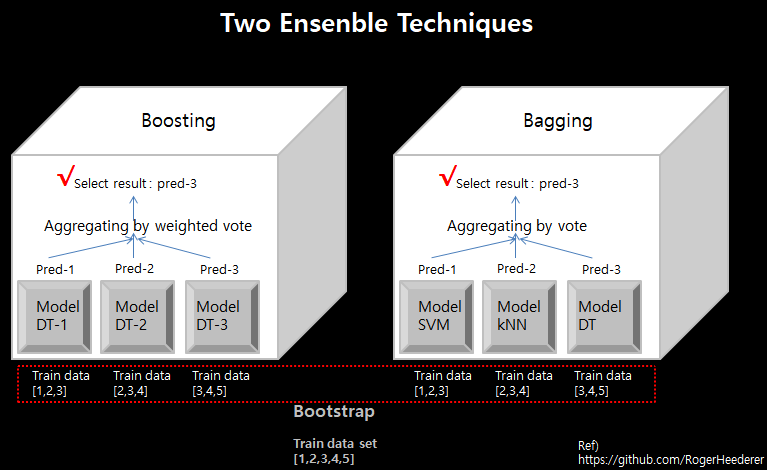
앙상블 기법에는 크게 2가지 종류로 나뉩니다. 바로 배깅과 부스팅입니다. 우선 배깅과 부스팅의 차이점은 학습 순서와 학습 알고리즘입니다. 아래 그림을 예로 설명하겠습니다.
Bagging
- 배깅은 부트스트랩을 통해 얻은 훈련 데이터를, 서로 다른 알고리즘으로, 병렬 방식으로 학습시켜, 3개의 classification model을 동시에 만듭니다.
그런 후, 각기 다른 모델들이 도출한 예측값들을 가지고 투표를 통해 Aggregating을 합니다. 이 투표에는 하드 보팅과 소프트 보팅이 있습니다. 하드 보팅은 각 모델들의 예측값을 보고, 다수인 레이블을 선택하는 것. 소프트 보팅은 모델들이 내놓은 레이블 마다 측정된 확률값을 각 레이블 단위로 전부 더하여 최종 분류 레이블을 선택하는 것입니다.
앙상블 기법은 모든 분류 모델에 적용 가능하지만, 주로 의사결정트리 모델에 적용합니다. 그 이유는 의사결정트리 모델이 과대적합에 빠지기 쉬운 모델이기 때문입니다. 그래서 bootstrap 샘플링 기법을 통해 데이터의 bias를 높인 다음, 이 데이터 샘플들로 의사결정트리 모델들이 학습하면 단 1개의 의사결정트리 모델이 전체 데이터를 학습한 결과보다 오버피팅될 확률이 적어집니다.
Boosting
- 부스팅은 부트스트랩을 통해 얻은 훈련 데이터를, 서로 같은 알고리즘으로, 순차 방식으로 학습시켜, model 1,2,3을 순서대로 만듭니다. 부스팅에서는 가중 투표 방식을 통해 Aggregating 합니다. 즉, 훈련된 모델들의 정확도 고려하여 weight로 반영합니다. 정확도가 높은 분류 모델의 결과값은 더 큰 힘을 받게 되는 것이지요.
#Aggregating - 여러 분류 모델들이 예측한 값을 조합해서 하나의 결론(레이블 선택)을 도출하는 과정
#RandomForest - 배깅을 적용한 의사결정트리